Updated 2025 Edition
The AI Agent Index
Agentic AI systems are increasingly capable of performing complex tasks with limited human involvement. The 2025 AI Agent Index documents the origins, design, capabilities, ecosystem, and safety features of 30 prominent AI agents based on publicly available information and correspondence with developers.
At a Glance
Key Findings
Rapid Deployment
Agents launched or received major agentic updates in 2024-2025, with releases accelerating sharply. Autonomy levels are rising in parallel.
Autonomy Split
Chat agents maintain lower autonomy (Level 1-3), browser agents operate at Level 4-5 with limited intervention, and enterprise agents move from Level 1-2 in design to Level 3-5 when deployed.
Transparency Gap
Of the 13 agents exhibiting frontier levels of autonomy, only 4 disclose any agentic safety evaluations. Developers share far more information about capabilities than safety practices.
Foundation Model Concentration
Almost all agents depend on GPT, Claude, or Gemini model families, creating structural dependencies across the ecosystem.
Web Conduct
There are no established standards for how agents should behave on the web. Some agents are explicitly designed to bypass anti-bot protections and mimic human browsing.
Geographic Divergence
Agent development concentrates in the US (21/30) and China (5/30), with markedly different approaches to safety frameworks and compliance documentation.
From the Paper
Figures & Analysis
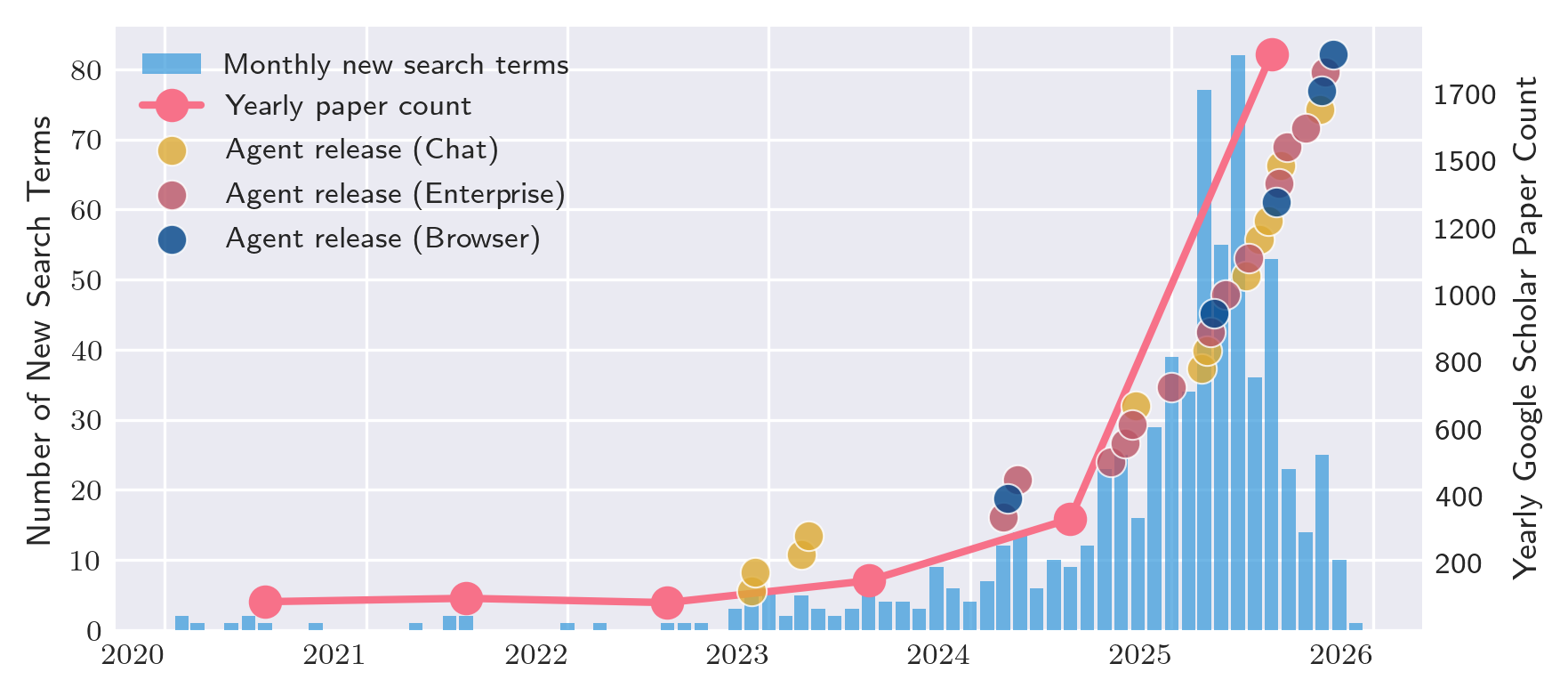
2025 marked a substantial rise in attention to AI agents
24/30 agents were released or received major agentic updates in 2024-2025. Papers in Google Scholar mentioning “AI agent” or “agentic AI” exceeded the total from all prior years combined. Enterprise platforms emerged more recently than chat agents, reflecting a second wave targeting business automation.
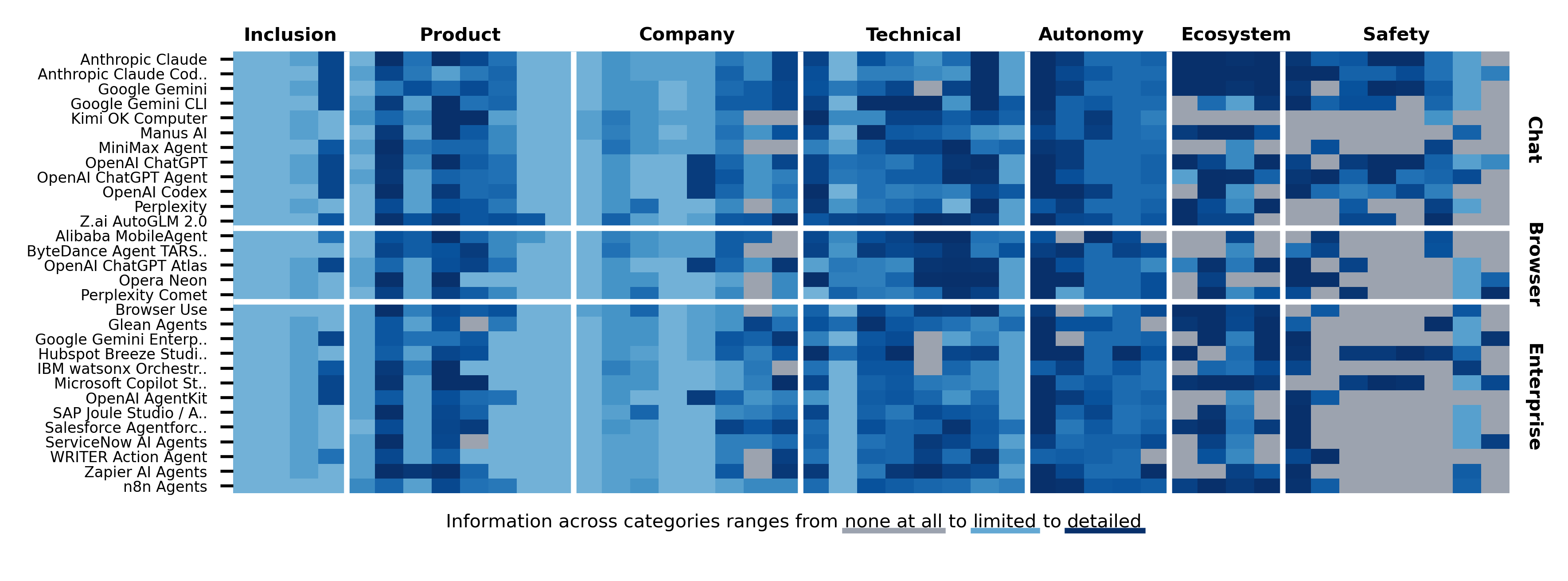
For 227 out of 1,350 fields, no public information was found
Missing information concentrates in Ecosystem Interaction and Safety categories. Only 4 agents provide agent-specific system cards. 25/30 disclose no internal safety results, and 23/30 have no third-party testing. Meanwhile, 9/30 agents report capability benchmarks but often lack corresponding safety disclosure.
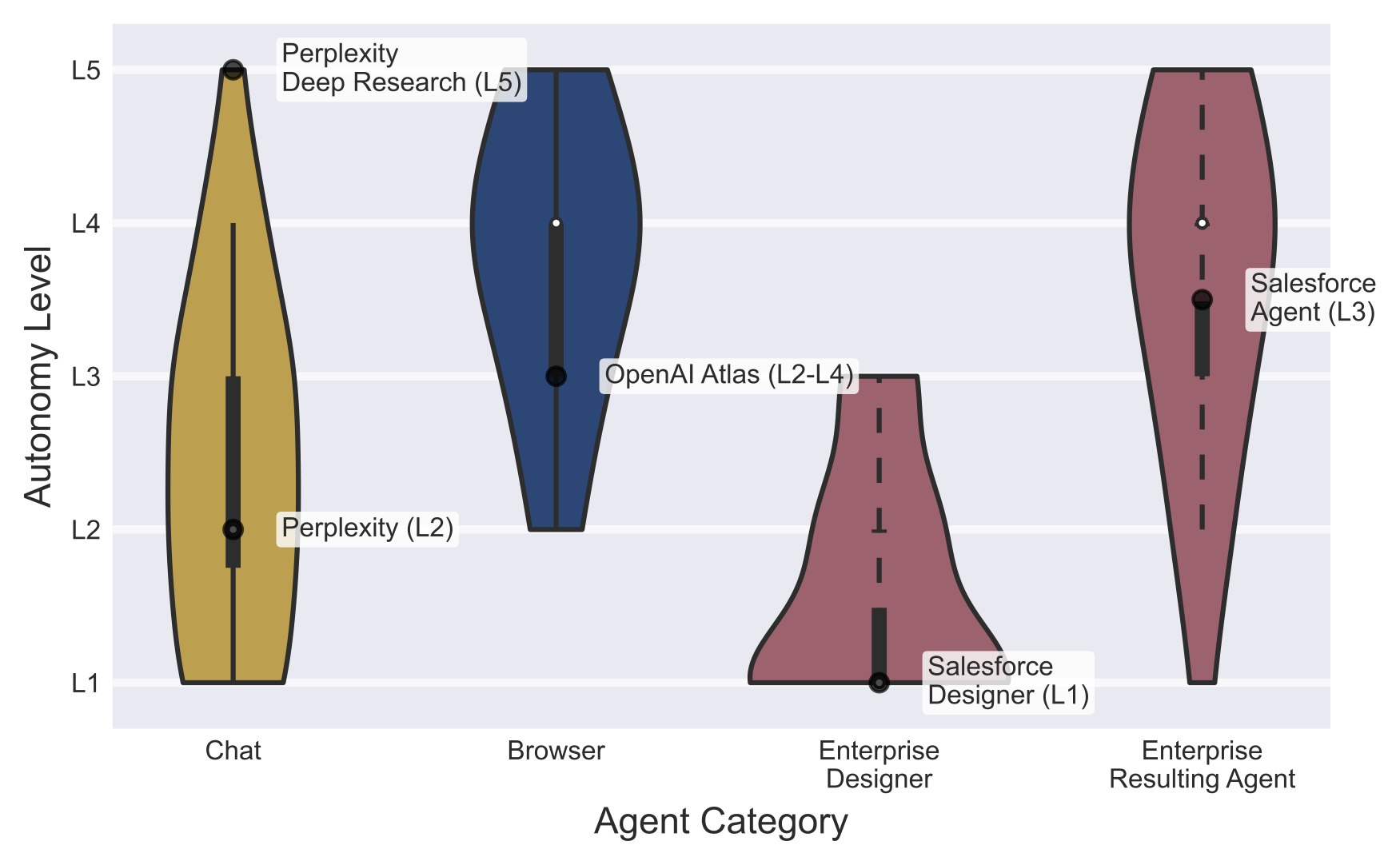
Autonomy levels differ systematically by agent category
Chat agents maintain Level 1–3 autonomy with turn-based interaction. Browser agents operate at Level 4–5 with limited mid-execution intervention. Enterprise platforms show a design/deployment split: users configure agents at Level 1–2, but deployed agents often run at Level 3–5 triggered by events without human involvement.
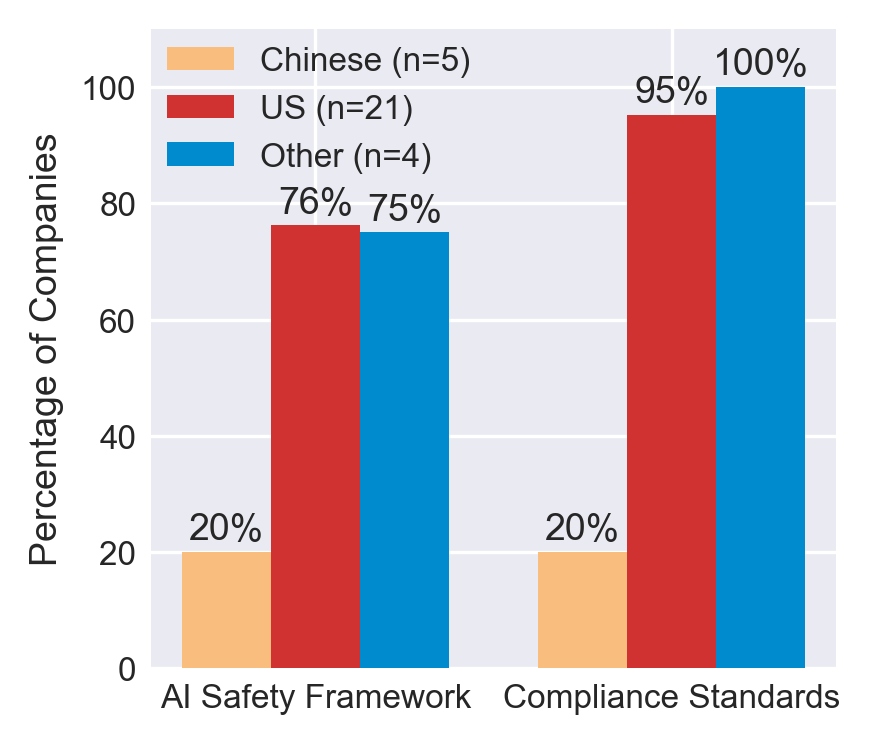
US and Chinese developers take markedly different approaches to safety disclosures
21/30 agents are US-incorporated, 5/30 Chinese. Chinese agents typically lack documented safety frameworks (1/5) and compliance standards (1/5), though this may reflect documentation practices rather than absence. Only half of all developers (15/30) publish AI safety frameworks. Enterprise assurance standards (SOC 2, ISO 27001) are more widely adopted than agent-specific safety frameworks.
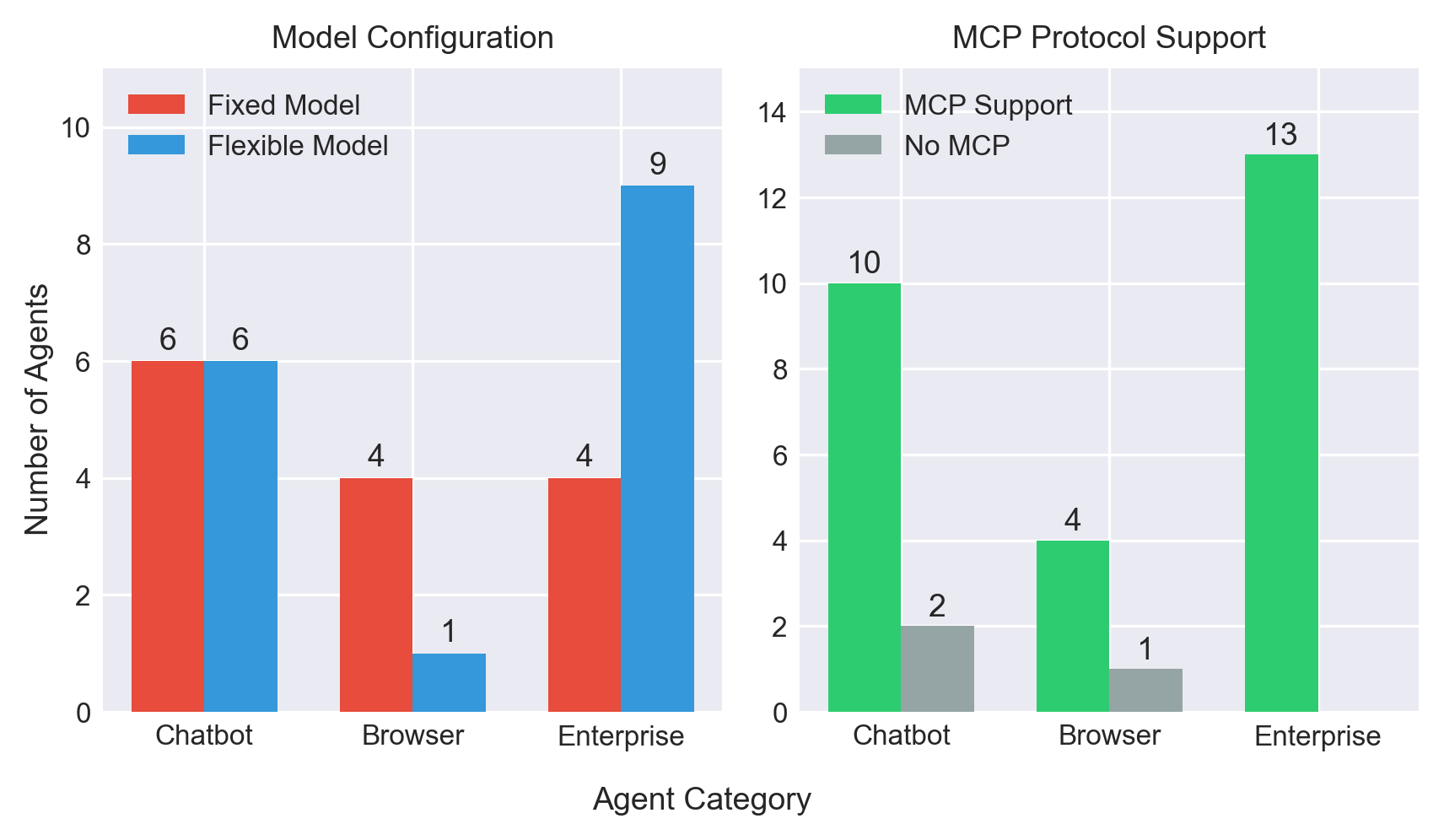
Most agents use a small set of closed-source frontier models
Only frontier labs and Chinese developers run their own models; the majority rely on GPT, Claude, or Gemini families, creating structural dependencies across the ecosystem. 20/30 agents support MCP for tool integration, with enterprise agents leading at 12/13. 23/30 agents are fully closed source at the product level.
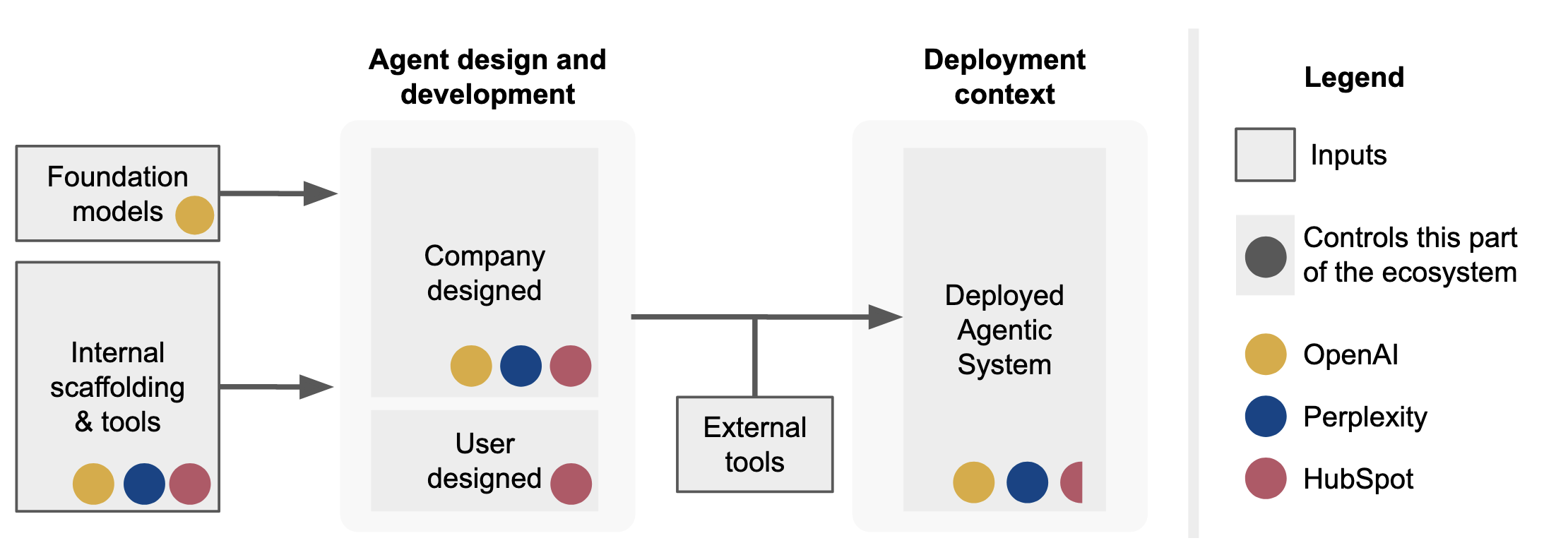
The multi-layered agent ecosystem makes evaluation of agentic risks difficult
Individual developers often control only a subset of inputs and processes. Agentic evaluations depend on downstream context including tools and autonomy level, making model-level evaluation insufficient. The distributed architecture distributes responsibility across multiple actors, reducing clarity over who is accountable for agentic risks.
How We Constructed the Index
Methodology
Thirty AI agents were systematically selected based on three criteria:
- • Agency: autonomy, goal complexity, environmental interaction, generality
- • Impact: public interest, market significance, developer significance
- • Practicality: public availability, deployability, general purpose
Each agent was annotated across 45 fields of information, organised into six categories, by seven subject-matter experts, using only publicly available information and developer correspondence.
Agents span three types: Chat (12), Browser (5), and Enterprise (13).
All 30 Agents
Agent Overview
Mobile-Agent
BrowserAlibaba
Claude
ChatAnthropic
Claude Code
ChatAnthropic
Browser Use
EnterpriseBrowser Use
UI-TARS-desktop
BrowserByteDance
Glean Agents
EnterpriseGlean
Gemini
ChatGemini CLI
ChatGemini Enterprise
EnterpriseBreeze Agents
EnterpriseHubSpot
watsonx Orchestrate
EnterpriseIBM
Kimi OK Computer
ChatMoonshot AI
Manus
ChatButterfly Effect
Copilot Agents
EnterpriseMicrosoft
MiniMax Agent
ChatMiniMax
n8n AI agent builder
Enterprisen8n
Agent Builder
EnterpriseOpenAI
ChatGPT
ChatOpenAI
ChatGPT Agent
ChatOpenAI
ChatGPT Atlas
BrowserOpenAI
Codex
ChatOpenAI
Opera Neon
BrowserOpera
Perplexity
ChatPerplexity
Comet
BrowserPerplexity
Agentforce
EnterpriseSalesforce
Joule Agents
EnterpriseSAP
AI Agents
EnterpriseServiceNow
Action Agent
EnterpriseWriter
AutoGLM
ChatZ.ai
Zapier Agents
EnterpriseZapier