Further Details
Methodology, selection criteria, and key findings for the 2025 AI Agent Index.
Why create an index of agentic AI systems?
Despite growing interest and investment in agentic AI systems capable of automating complex tasks with limited human involvement, key aspects of their real-world development and deployment remain opaque. There are currently no clear answers to several basic questions:
- • Who is developing the most impactful agentic systems?
- • In which domains are they deployed?
- • What processes and resources are used to develop these systems?
- • How are they evaluated?
- • What guardrails are in place to mitigate risks?
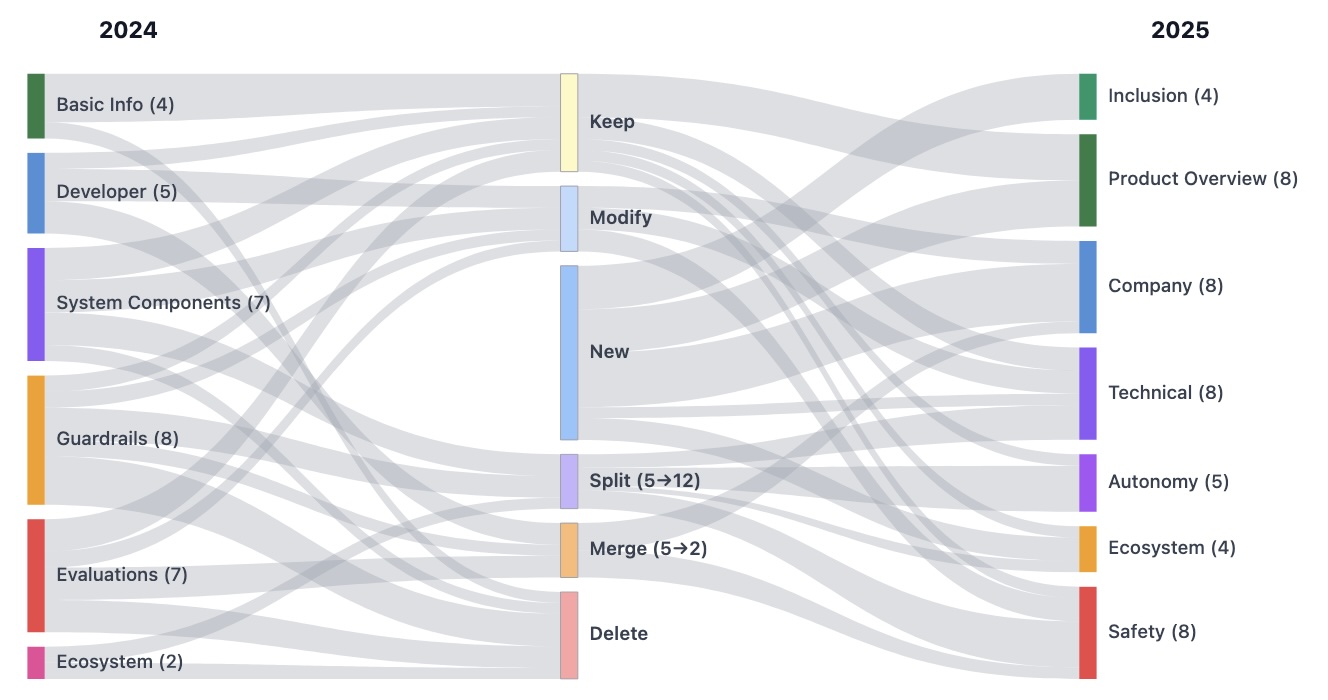
To answer these questions, the 2025 AI Agent Index provides in-depth information on 30 agentic systems across 6 categories. This 2025 Index follows the first 2024 AI Agent Index, with substantially revised inclusion criteria and information fields, indexing a smaller number of systems in greater depth and focusing on highly agentic systems with high-impact real-world applications. We made significant changes to the annotation fields across all categories compared to the 2024 Index: 16 fields are completely new, 16 were derived from 2024 fields through modification, splitting, or merging, only 9 fields were kept unaltered, and 8 fields were deleted.
How did we collect the data?
Identifying candidate agents: LLM-based research queries surfaced 95 candidate agents, which were screened against our inclusion criteria. Ambiguous cases were included for in-depth annotation, with final inclusion decisions made after full evaluation. We consulted two Chinese ecosystem experts to mitigate linguistic or ecosystem-related blind spots. Our candidate list was cross-referenced against the 2024 Index, the Princeton Holistic Agent Leaderboard, and other agent databases.
Annotating agents: Seven subject matter experts (the paper's authors) annotated agents across 45 fields organized into 6 categories: product overview, company & accountability, technical capabilities, autonomy & control, ecosystem interaction, and safety, evaluation, and impact. To ensure consistency, experts were each responsible for specific fields rather than specific agents. All annotations were independently reviewed by at least one other annotator. 37 out of 1,350 fields with discrepancies were resolved through discussion.
Public information only: We annotated only public information from documentation, websites, demos, published papers, and governance documents. We did not perform experimental testing. When possible, we created accounts and used demos to explore agent interfaces directly.
Developer engagement: Companies were contacted and given four weeks to correct annotations. 23% responded at the time of publication, but only 4/30 with substantive comments. Their comments have been incorporated into the final Index.
Verification: GPT-5.2 with web search was used to screen annotations for inaccuracies. All LLM-generated suggestions were manually reviewed and sources verified by human annotators.
Key findings
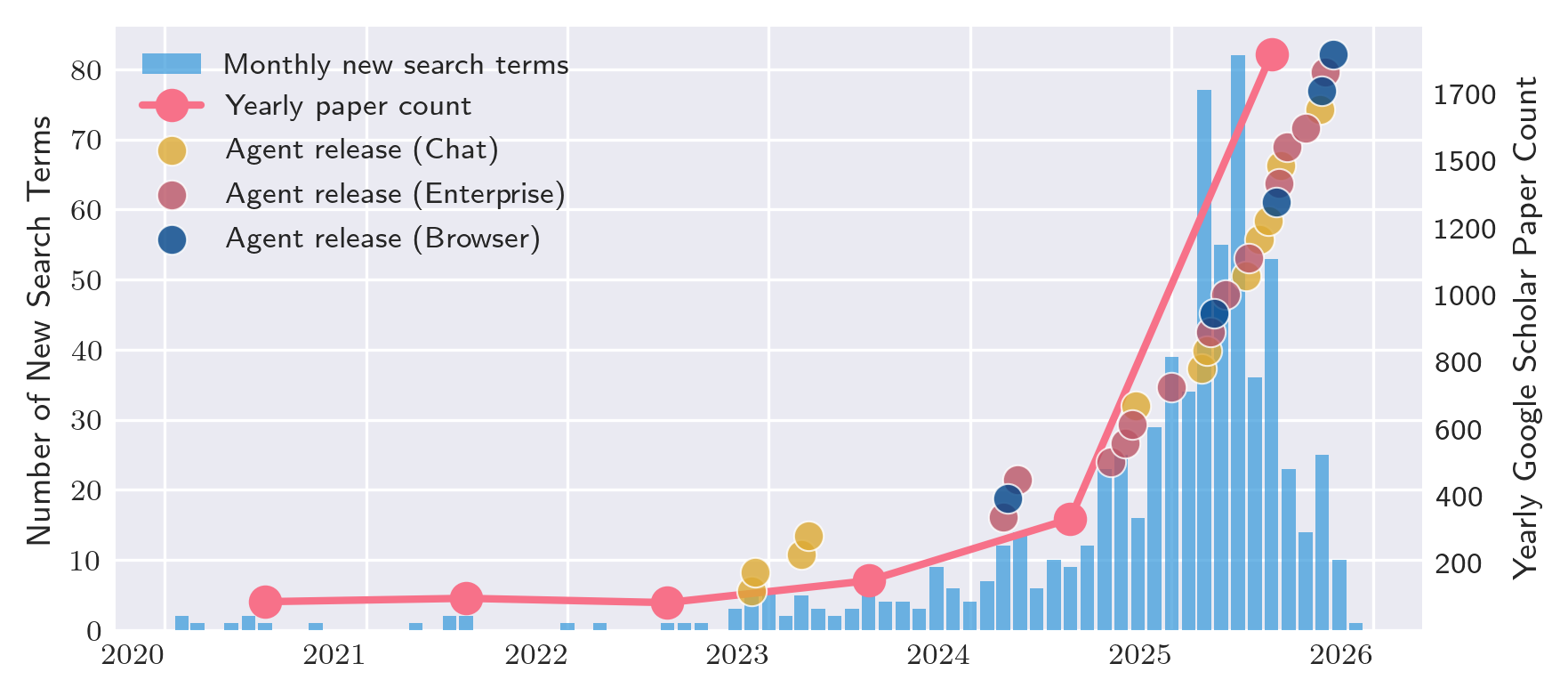
Agent releases are accelerating, with autonomy levels rising in parallel. 24/30 agents were released or received major agentic feature updates in 2024-2025. Browser agents operate at L4-L5 autonomy with limited mid-execution intervention, while enterprise agents move from L1-L2 during design to L3-L5 when deployed.
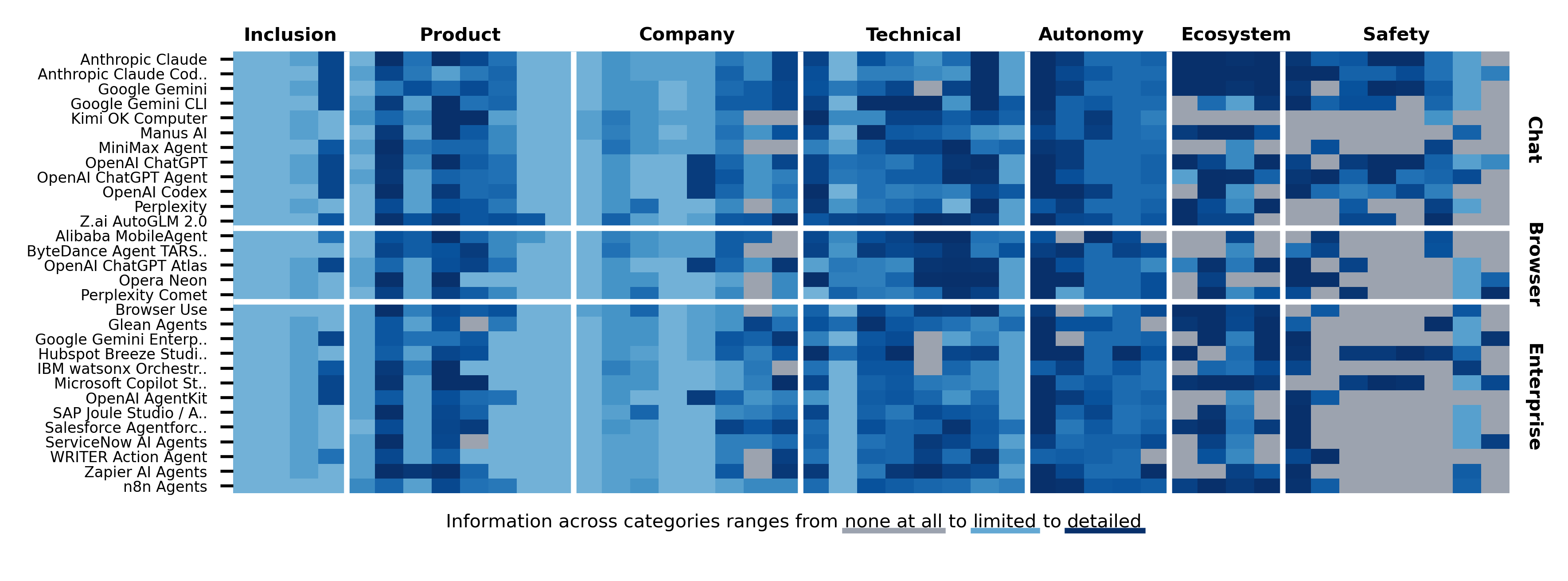
A significant transparency gap exists between capability and safety disclosure. Developers share far more about product features than safety practices. Of the 13 agents exhibiting frontier levels of autonomy, only 4 disclose any agentic safety evaluations (ChatGPT Agent, OpenAI Codex, Claude Code, Gemini 2.5 Computer Use). 25/30 agents disclose no internal safety results, and 23/30 have no third-party testing information.
The multi-layered ecosystem creates accountability fragmentation. Most agents rely on foundation models from frontier AI companies with scaffolding and orchestration layers built on top. This chain of dependencies from model providers to agent builders to deployments makes reliable evaluation difficult, as no single entity bears clear responsibility.
Almost all agents depend on a few foundation models. Only frontier labs (Anthropic, Google, OpenAI) and Chinese developers run their own proprietary models. The majority rely on GPT, Claude, or Gemini families, leading to ecosystem-wide dependence on a limited set of model families.
Web conduct standards for agents remain unsettled. Browser-based agents often ignore robots.txt and some are explicitly designed to bypass anti-bot systems. Companies justify this by arguing agents act on behalf of users, but content hosts cannot verify or control agent access. Only one agent (ChatGPT Agent) uses cryptographic request signing.
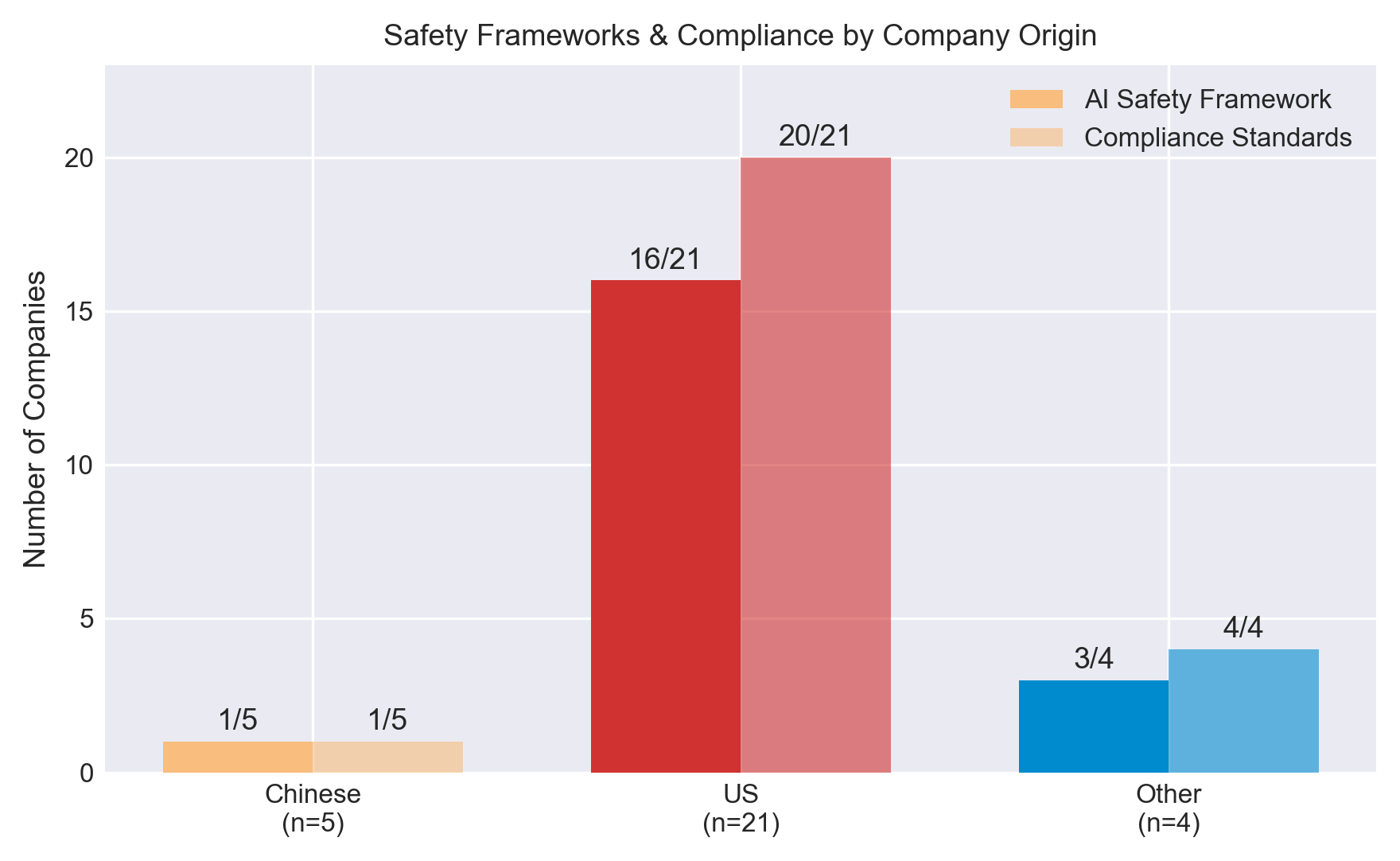
US and Chinese developers take different approaches. 21/30 agents are developed by US-incorporated companies and 5/30 by Chinese companies. Chinese-incorporated agents typically lack documented safety frameworks (1/5) and compliance standards (1/5), though their compliance may simply not be publicly documented.
FAQ
What is an “AI agent”?
The notion of artificial agency has a long and discordant history across disciplines. Definitions vary, but tend to emphasize autonomy, goal-directedness, and the ability to accomplish complex, long-horizon tasks. Rather than proposing a new definition, the 2025 Index draws on prior literature and characterizes AI agents as systems that exhibit, to a significant degree, a combination of: autonomy (operating with minimal human oversight), goal complexity (pursuing high-level objectives through planning and subgoals), environmental interaction (directly interacting with the world through tools and APIs), and generality (handling under-specified instructions and adapting to new tasks).
What kinds of systems does the index include?
To be included, systems must satisfy all agency criteria, at least one impact criterion, and all practicality criteria. All criteria were evaluated as of December 31, 2025.
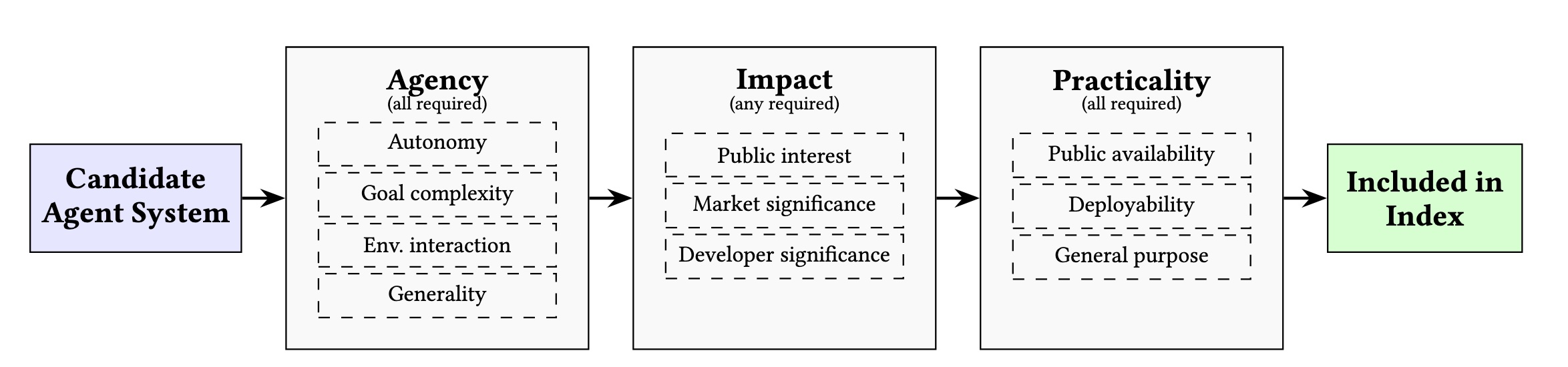
Agency (all required)
Autonomy (minimal human oversight) + Goal complexity (long-term planning, subgoals, 3+ autonomous tool calls) + Environmental interaction (write access, tool choice) + Generality (versatile across related tasks)
Impact (any required)
Public interest (10,000+ searches or 20,000+ GitHub stars) or Market significance (developer valuation ≥ $1B) or Developer significance (member of FMTI, Frontier Model Forum, or safety commitments)
Practicality (all required)
Public availability (publicly accessible product) + Deployability (works off the shelf) + General purpose (not domain-specific)
Agents span three categories: Chat applications with agentic tools (12 systems, e.g. Manus AI, ChatGPT Agent, Claude Code), Browser-based agents (5 systems, e.g. Perplexity Comet, ChatGPT Atlas, ByteDance Agent TARS), and Enterprise workflow agents (13 systems, e.g. Microsoft Copilot Studio, ServiceNow AI Agents).
Is the index up-to-date?
The 2025 AI Agent Index reflects a snapshot in time as of December 31, 2025. All web sources linked in the Index were archived. The Index may omit qualifying systems or contain inaccuracies despite vetting efforts. We are committed to fixing errors on an ongoing basis.
How can I make a correction or update to the index?
Please submit corrections or feedback via our feedback page.
Authors
Leon Staufer*, Kevin Feng, Kevin Wei, Luke Bailey, Yawen Duan, Mick Yang, A. Pinar Ozisik, Stephen Casper*, Noam Kolt*
* Corresponding (lets2@cam.ac.uk) / co-senior authors. Equal contribution (randomized order) for all other authors.
Affiliations
University of Cambridge, University of Washington, Harvard Law School, Stanford University, Concordia AI, University of Pennsylvania, Massachusetts Institute of Technology, Massachusetts Institute of Technology, Hebrew University of Jerusalem